Epistomata
Epistemic automata
Epistomata is an experiment to put symbolic AIs in a graphicless RPG-like environment, so that they can share knowledge and make plans.
The final goal is that an agent can pass the Sally-Ann test. This means that agent A understands that other agent B has a different set of knowledge than A has, and that A can predict what B will do according to B’s knowledge.
You can find the code in bitbucket
Environment design
The design is the simplest possible environment:
- Discrete time, turn based.
- Discrete space, cell based.
- Deterministic.
- Single action per turn.
Agents design
- Agents have a mental model (or simply called knowledge).
- Mental models contain objects, goals and actions, which can be modified.
- Mental models are recursive. Inside an agent’s mental model, the objects represented may have internal mental models represented as well.
- Actions are planned depending on utility towards the goal.
Testing
Planning to adquire knowledge as a step to a goal
One scenario I used to develop and test these agents, is a situation where the agent doesn’t know how to achieve a goal, but knows that it can learn an action that allows getting the goal.
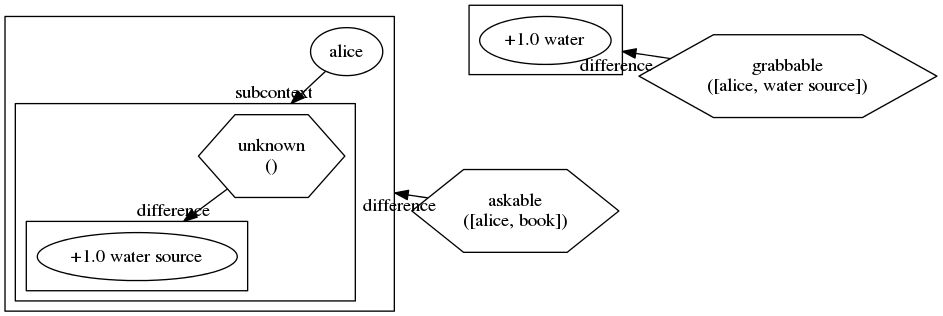
For instance, the agent Alice wants to get water. Alice knows that she can grab water from a “water source”, and Alice also knows that she can learn where there is a water source by reading a book. Or more technically, Alice knows that if alice asks a book, the mental model of Alice will change, adding an “unknown” action that if triggered will make appear a “water source”.
Next image is Alice’s knowledge:
- Hexagons are actions, or traits that can be triggered.
- Circles are objects.
- The “difference” arrows are the consequences of a change.
- The “subcontext” arrows point to meta knowledge.
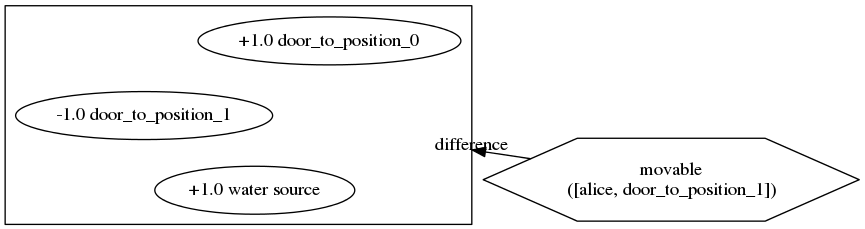
And the book knows that if Alice moves through the door to position 1, a water source will appear, the door back to position 0 will appear, and the door to position 1 will disappear:
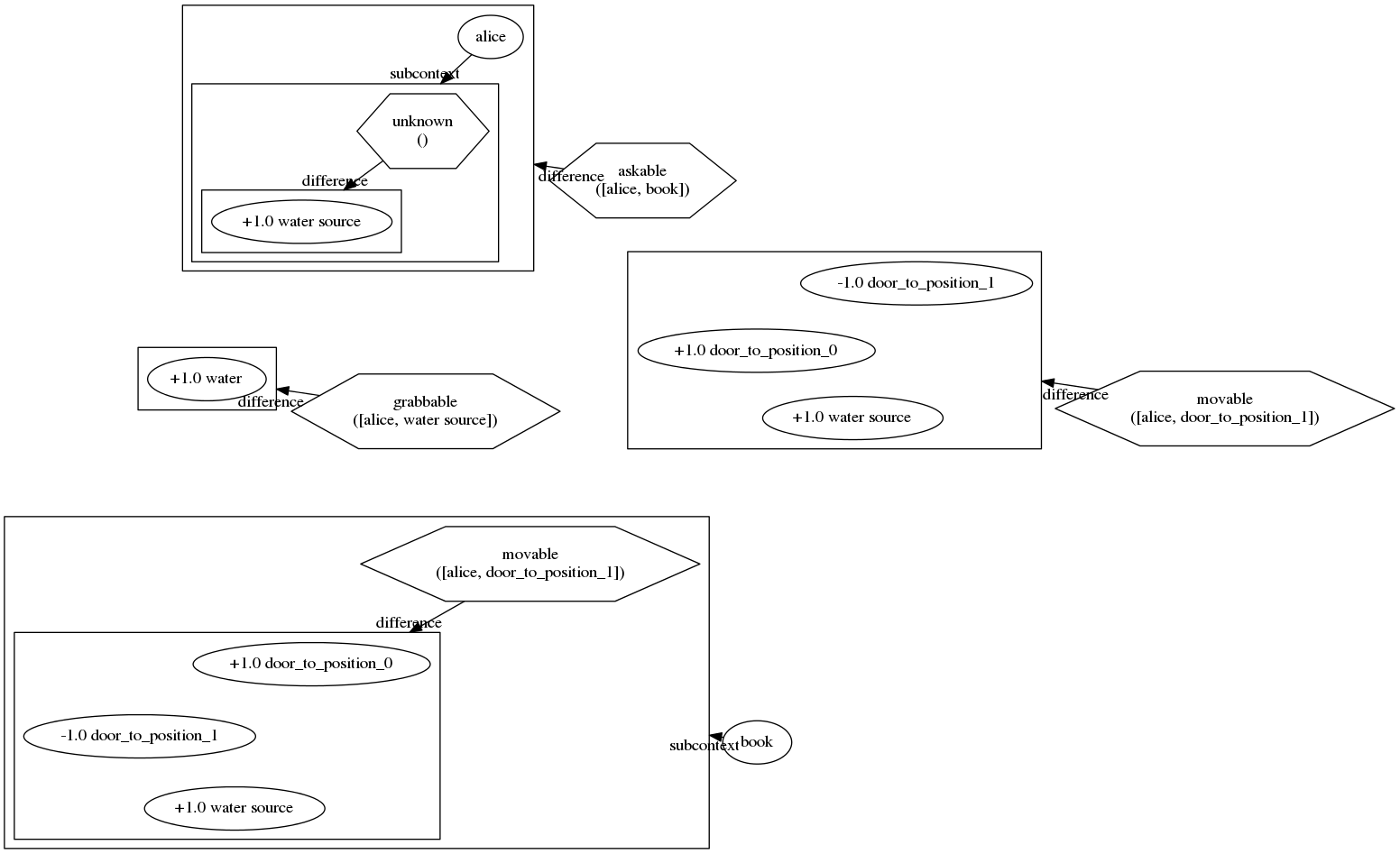
Then, Alice decides to do the action of asking the book, and after asking she learns to move, and also learns what the book knows:
Details
Learning from unexpected changes
Once an agent decides to perform a change, it will modify the certainty of that change, depending on the results of the change. If the results match the expectation, the certainty of the change will be increased. If the results don’t match, the certainty will be decreased and a new change (describing the actual results) will be added to the knowledge.
The downside of this learning system is the bootstrap. To improve the knowledge about a change, it needs to try it, and unless it decides the change can help with the goal, it won’t be tried. This is because there’s no implementation of exploration. This implies the need to provide some initial knowledge about the possible actions that the agent can do.
Next steps
The current architecture supports meta-knowledge, so it’s a good starting point to use the knowledge about other agents to predict their behaviour.
The hard part here is to find out the actual algorithm that the other agent will use. It’s easy to assume they will use the same planning algorithm, but that approach is quite limited.